In the world of statistics and data analysis, understanding the relationship between two variables is crucial. One of the most fundamental tools used for this purpose is correlation. Correlation measures the strength and direction of a linear relationship between two variables. Whether analyzing stock prices, medical research data, or student performance, correlation plays a critical role in interpreting how variables interact.
Key Summary
- Correlation is a statistical measure that expresses the extent to which two variables change together.
- If an increase in one variable tends to be associated with an increase in another, the correlation is positive.
- Conversely, if an increase in one variable tends to be associated with a decrease in another, the correlation is negative.
- When the value of one variable increase while the other variable neither increases nor decreases, indicates that there is no apparent linear relationship.
Example
Let’s consider diabetes in the India. Imagine you’re an epidemiologist focused on nutrition, looking into the diabetes epidemic specifically. You’re interested in understanding which factors are linked to the percentage of people who are diabetes. You can start creating scatter plots after the data collection to explore potential relationships between different numerical variables and diabetes rates across India.
We can collect data of different states in India having diabetes. When collecting data, we can collect different aspects on individual like lifestyle (eating fruits and vegetables), smokers, air pollution or diet to gauze the association between diabetes.
Positive Association between variables – Percentage of Diabetes Vs Smokers
We can use these variables in scatter plots to explore relationships, like this scatter plot showing the percentage of people who are diabetes compared to the percentage who smoke. In this example, we can see that the x-axis represents the percentage of smokers, while the y-axis shows the percentage of people classified as diabetes.
You can observe quite a bit of variation in the data, but one noticeable pattern stands out. States with a lower percentage of smokers generally also have a lower percentage of diabetes individuals, though this isn’t always the case. Similarly, states with a higher percentage of smokers tend to show higher diabetic rates as well.
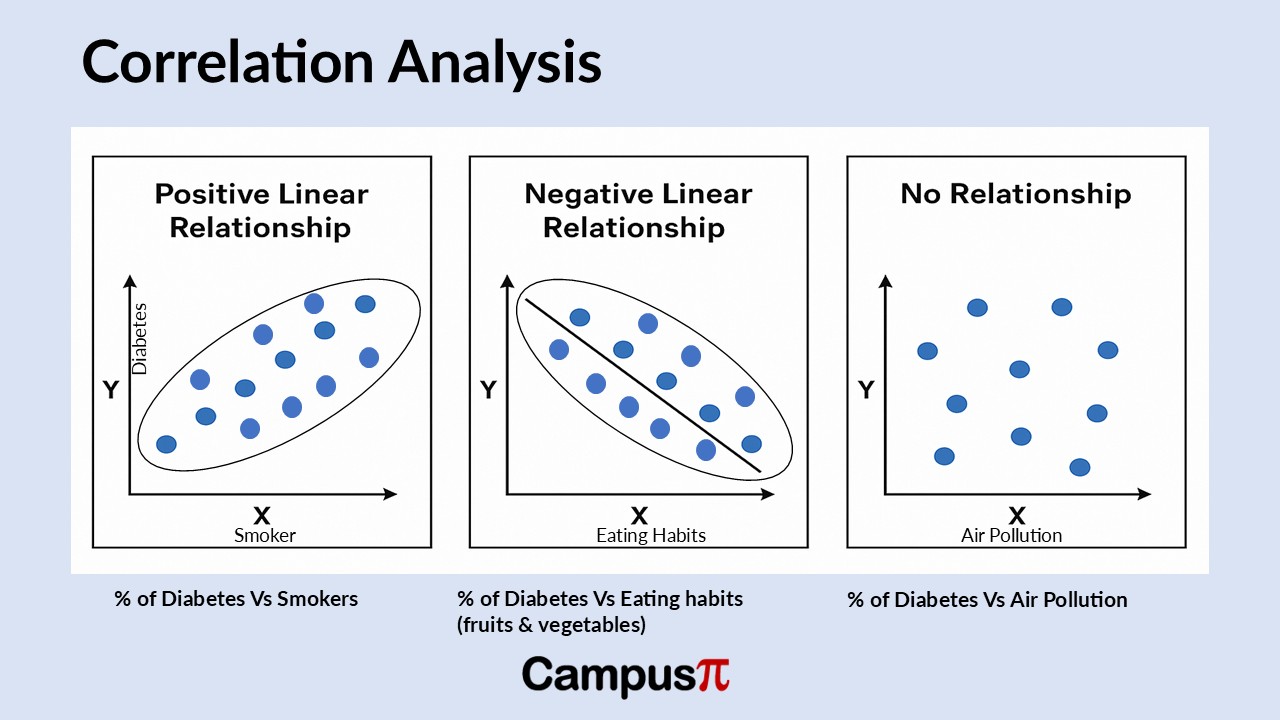
When values increase or decrease together, it indicates a positive linear relationship. For example, in each state, as the percentage of smokers rises, the percentage of individuals who are diabetes tends to rise as well. This creates an upward-sloping pattern in the data, reinforcing the idea of a positive linear relationship between these two variables.
You can envision this pattern as being roughly approximated by a straight line, which is what we refer to as linear. The term “linear” relates to the concept of a line and indicates that there is a straight-line relationship present, even if we aren’t fitting an actual line to the data. The data shows a pattern that implies a straight-line relationship, and it’s considered positive because both variables increase together and decrease together. Thus, we describe this relationship as a positive linear relationship.
Negative Association between variables – Percentage of Diabetes Vs Eating habits (eating fruits and vegetables)
Now, let’s examine a different set of variables from our dataset, specifically the percentage of diabetes individuals and the percentage of people who report eating fruits and vegetables. On the x-axis, we have the percentage of people eating fruits and vegetables, while the y-axis represents the percentage of diabetes individuals in each state. The pattern here differs slightly, showing a downward slope. When we look at the scatter plot, we can observe that states with a low percentage of people consuming fruits and vegetables tend to have a higher percentage of diabetes individuals.
The quadrant indicates that states with a high percentage of individuals consuming fruits and vegetables tend to have a lower percentage of diabetes individuals. Therefore, we can conclude that as the percentage of people eating fruits and vegetables increases, the percentage of obesity decreases.
In general, when the value of one variable increase while the other decreases, we can identify this as a negative linear relationship. Similarly, when one variable’s values decrease while the other increases, we can also describe this as a negative relationship. The pattern is consistent in both scenarios, and we can observe a downward-sloping trend in the data. You can envision fitting a straight line through this set of data to illustrate this relationship.
No Association between variables – Percentage of Diabetes Vs Air Pollution
Now, let’s examine a different scatter plot that displays the percentage of diabetes individuals and the air pollution in each state. Focusing on states with a low percentage of air pollution, we can observe that within this group, it’s difficult to draw any conclusions about the diabetic percentage. There seems to be a roughly equal distribution of states with low, medium, and high percentages of obesity.
When we examine states with a high percentage of air pollution, we find a roughly equal distribution of diabetic rates. Here, we can observe that there is a similar mix of states with high, medium, and low percentages of obesity.
This type of pattern in the data, where the value of one variable increase while the other variable neither increases nor decreases, indicates that there is no apparent linear relationship. Essentially, there is no discernible pattern in the data, resembling a cloud of points. Therefore, based solely on the scatter plots, we cannot identify a clear relationship between the variables.
Conclusion
We can begin to draw conclusions about obesity and the relationships between one numerical variable and a set of other numerical variables. Based solely on scatter plots, we can identify a general positive linear relationship between the percentage of diabetes individuals and the percentage of people who smoke cigarettes. This means that as the percentage of smokers increases, the percentage of diabetes also rises. Conversely, we can observe a negative linear relationship between the percentage of diabetes individuals and the percentage of those consuming fruits and vegetables.
Finally, we can conclude that there is no linear relationship between the percentage of air pollution and the percentage of diabetes individuals. As the percentage of air pollution increases, there is no significant overall change in the diabetes percentage. This observation leads us to consider that while scatter plots are useful for visualizing the relationship between two numerical variables and can suggest potential patterns, we may want to calculate a summary measure of association instead of relying solely on graphical interpretation. Also, it is important to note that correlation does not imply causation. Just because two variables are correlated does not mean one causes the other to change.