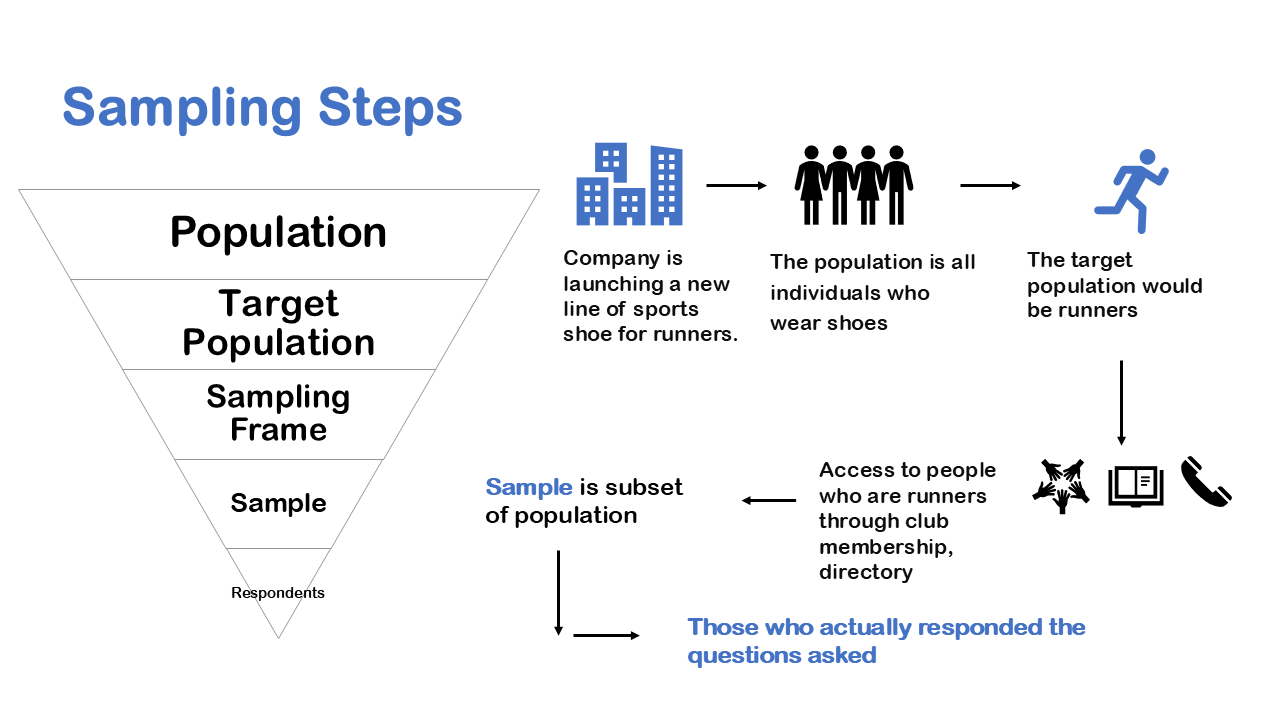
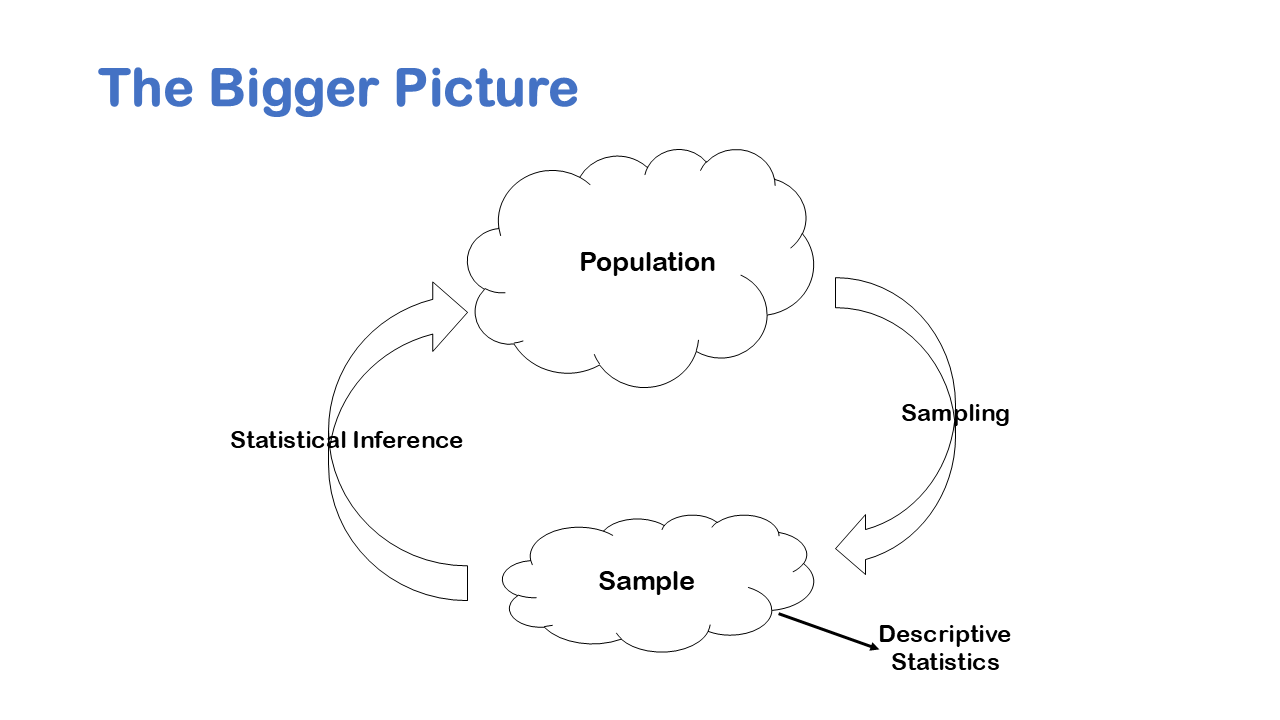
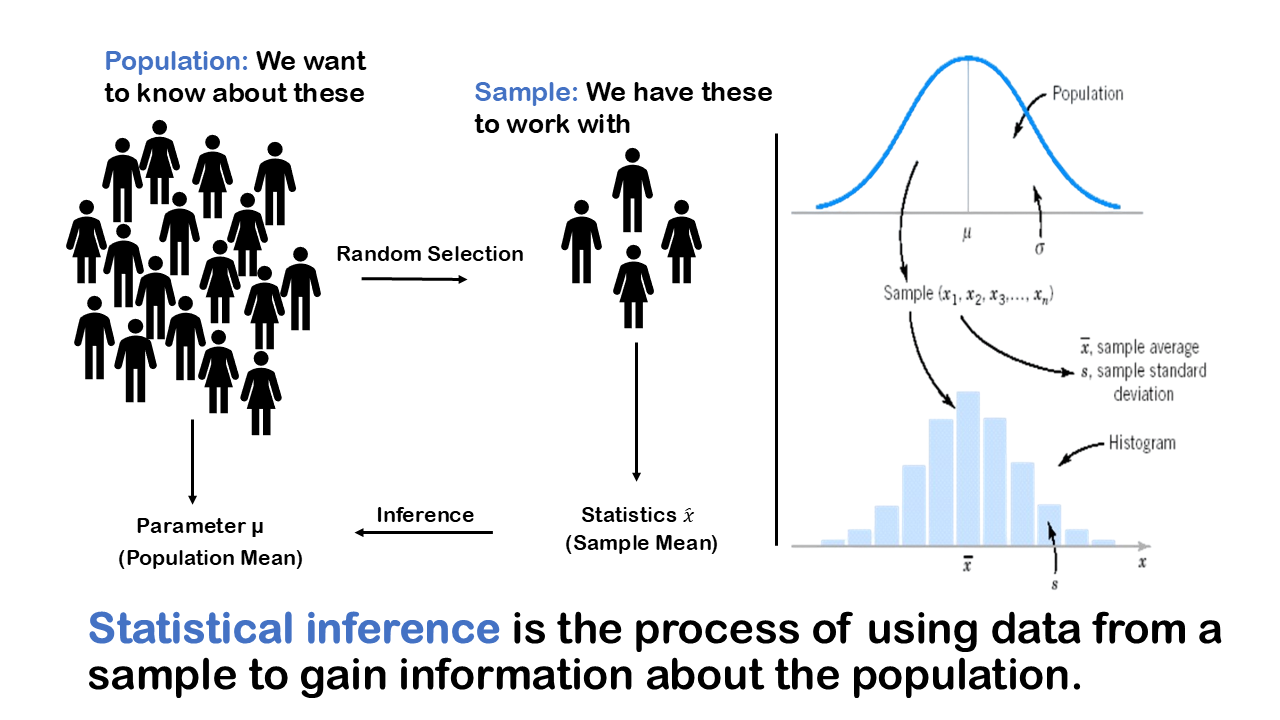
Bar Graph-two categorical variable
In the previous article, we have discussed tabulating and graphing one categorical variable through table of count and proportion. We also discussed in another article about tabulating two categorical variables through contingency table. We also saw in another article how the conditioning matters through conditional and marginal distributions by taking example of relationship status and gender. So, in this article of categorical data, we will discuss how to visualize categorical data. We will talk about dodged, staked bar graphs. We will also discuss what is called a Mosaic plot in another article? To visualize the two categorical variables, we use both dodged and stacked bar graphs. Bar graphs can be used to display relative frequencies or proportions or percentages but here we will focus on bar graphs of counts.

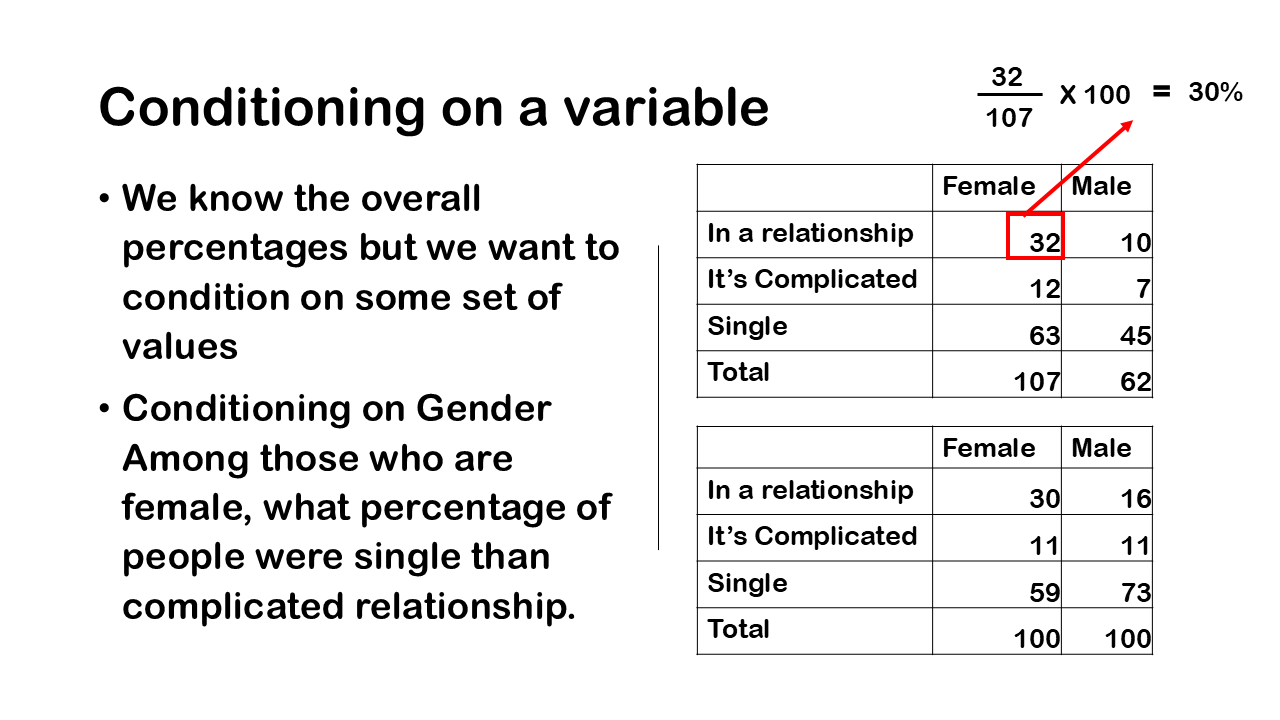
Referring to our contingency table of counts we have 169 total number of people. We also have the total counts for those in a relationship, in a complicated relationship or single and total counts of female and male. And then, we have the cells of this contingency table which are the different counts at different levels. So, for example we have 32 people who are in relationship and are female. Then we have 10 people who are in are in relationship are male.
So, for a contingency table of counts, we can think of graphing the marginal or unconditional distributions using a simple bar graph which is displayed. The bar graph is showing the unconditional distribution of those who are female and male. Across the other categorical variable of relationship status, we have three level of those who are in a relationship, in a complicated relationship or single.
Overall, 42, 19, 108 people that’s shown in this bar graph for relationship status, and 107 and 62 as male and female. So, reiterate again, these are the frequencies or counts for the unconditional distributions
Dodged bar graph -side by side bar graph

Plotting the total unconditional distribution is straight forward as we have seen earlier. The above graph shows clearly how to plot these distributions. The question we have is these cells in the middle highlighted in red box that reflect the cross tabulation of the different values for a categorical variable, how do we graph. The solution is to create a bar graph that are either dodged or stacked
Gender with relationship status
Let’s look at a dodged bar graph, this is a bar graph in which we’re looking at those who are female and those who are male and then among those who are female or male, we’re looking at the counts for whether you’re in a relationship, in a complicated relationship or single. We call this dodged Because the actual bars are compressed next to each other, or side by side.
We can see that all we’re doing is we’re just representing the cells here. We have six cells and we have six bars, we’re just grouping the bars based on whether you’re female or male. When looking at these cells, we know we have different heights and we can see that most people in our data set are those in the group, who are female and single, that’s the highest bar out of these cells. We can also look at a different sort of way of creating a dodged bar graph instead of grouping by whether or not you are male or female.
Relationship status with Gender
We can also group the cells based on whether you’re in a relationship, in a complicated relationship or single. This is the same kind of graph as before the heights of the bars are the same, we’re just orienting whether or not you are female or male versus the relationship status. In this case we’re just chunking our data into whether you’re in in a relationship, in a complicated relationship or single than with an each of those levels or categories, so we have three columns rather than two in previous example and those three levels are again bifurcated into whether you are male or female.
It’s just a slightly different way of looking at the data, but we’re doing is we’re just representing the counts or frequencies in the cells in a contingency table and the heights of the bars, just still representing the number of counts for each of those cross tabulations
Stacked bar graph – Gender with relationship status

Now besides dodged bar graphs, we can also think about stacking the bar graph i.e. instead of looking at side by side, we just stack them on top of each other. In this case also what we’re doing is we’re just representing the cells of a table of counts as different bars.
As in the previous case, we’re creating a stacked bar graph in which we’re chunking our data into female or male and then we’re plotting as within each bar the number of counts for those with the relationship status.
So, you can see here that again the greatest bar is represented by females who are single, that just reflects the same information in a dodged bar graph, but sometimes a stacked bar graph can be more informative or just a more concise way of visualizing the cells.
Relationship status with Gender
We could also look at a stacked bar graph by just chunking the relationship status as in the previous case. So, we’re looking at relationship status first, and then within each level we’re looking at the number of counts who are female or male. Both the graphs dodged and stacked conclude the same thing. Also change in the orientation of the graph will also not change anything, it’s just a different way to represent the data.












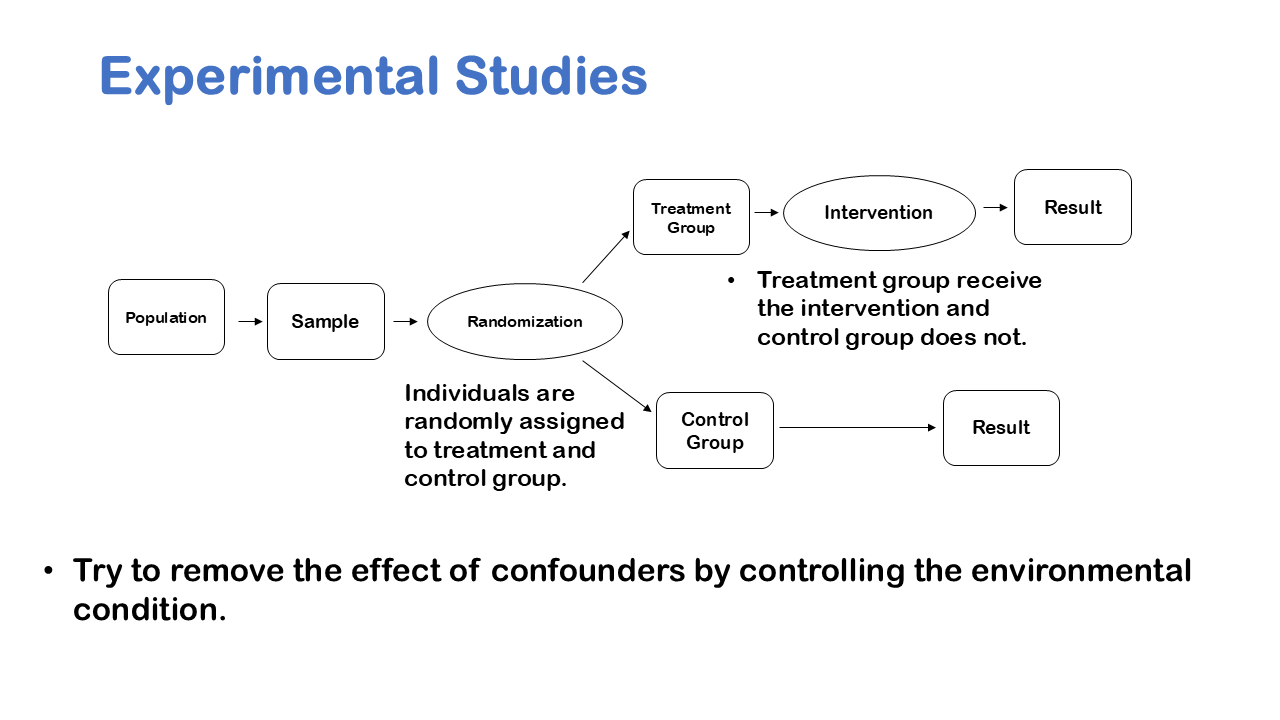
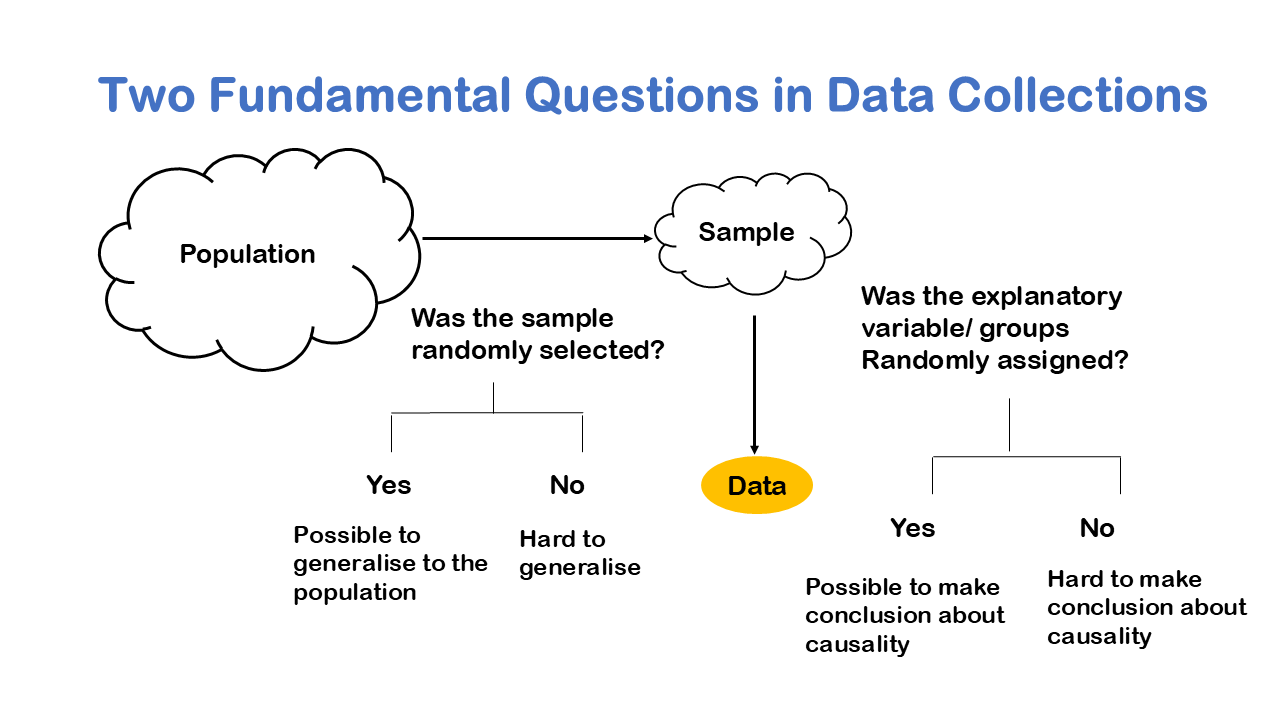
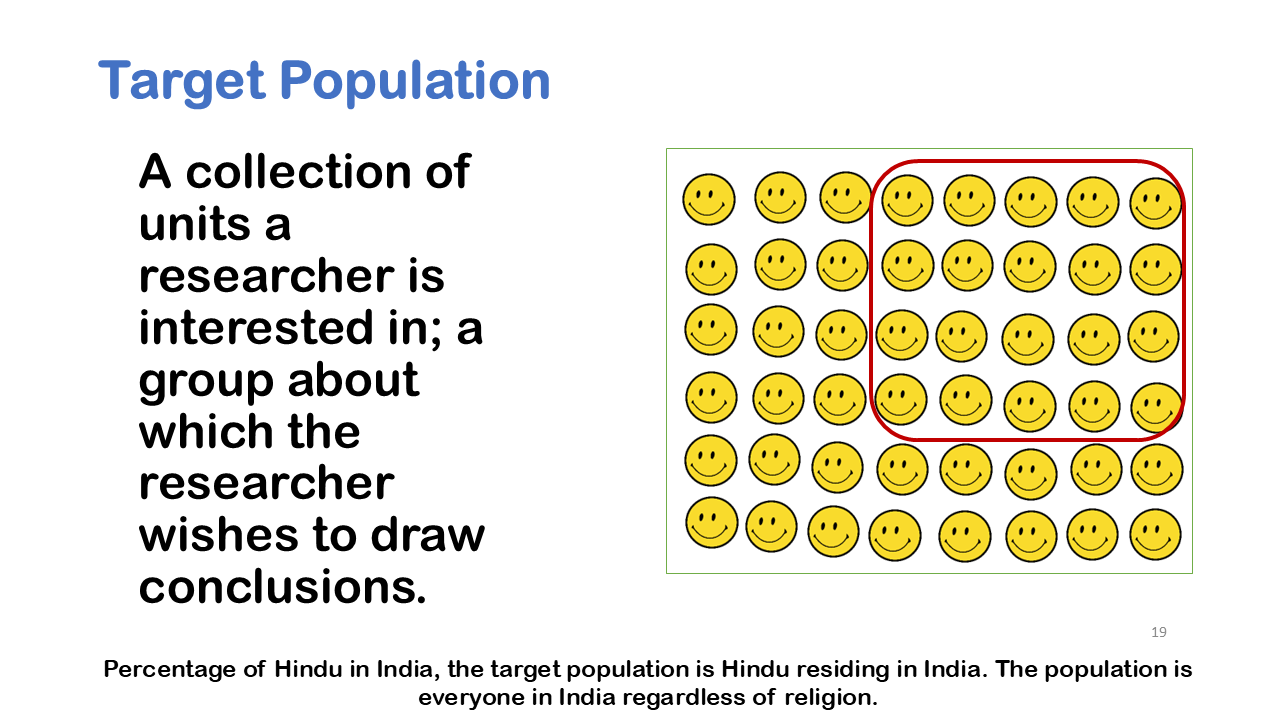
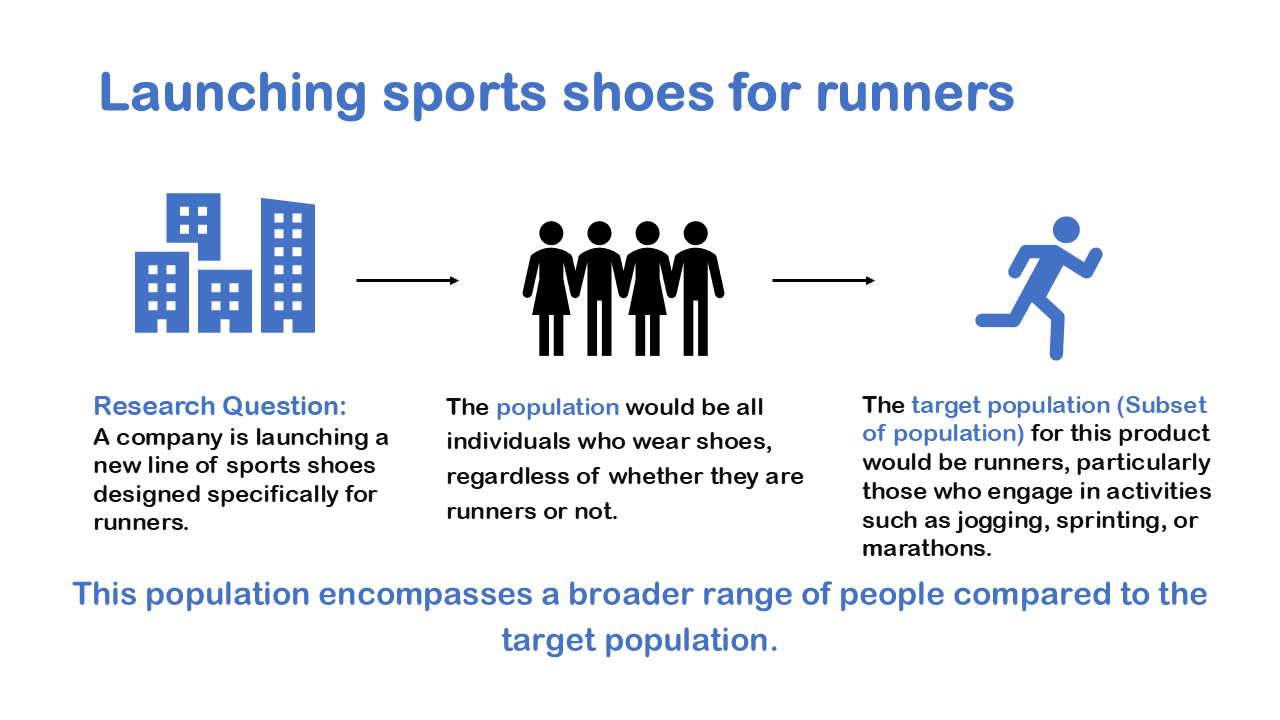
 We can take an example of Obesity to understand the nuance, it’s very tempting to say that you know if you get fat, then you’re causing your friends to get fat, because of social structure. But it’s very possible that maybe a fast-food restaurant opened down the street has changed your eating habits. So, what appeared to be a cause-and-effect pattern due to social structure of friends was really caused by the fact that a fast-food restaurant opened down the street. We like to see cause and effect relationships for better conclusive results, when we have an experiment it’s much easier to prove cause and effect.
We can take an example of Obesity to understand the nuance, it’s very tempting to say that you know if you get fat, then you’re causing your friends to get fat, because of social structure. But it’s very possible that maybe a fast-food restaurant opened down the street has changed your eating habits. So, what appeared to be a cause-and-effect pattern due to social structure of friends was really caused by the fact that a fast-food restaurant opened down the street. We like to see cause and effect relationships for better conclusive results, when we have an experiment it’s much easier to prove cause and effect.