


Unlike the mean and median, which represent average and middle values respectively, the mode identifies the most frequently occurring value in a dataset. Calculating the mode is straightforward. You first list all values in the dataset, and then identify which value appears most frequently. This value is considered the mode.
In practice, statistical software is often used to calculate the mode, especially when dealing with large datasets. Just as we rely on software for calculating the mean and median efficiently, using statistical tools ensures accuracy and saves time in identifying the mode, particularly in datasets with numerous observations.
The mode offers valuable insights into the typical or predominant value within a dataset. It’s particularly useful in scenarios where identifying the most common occurrence is important, such as in analyzing consumer preferences, exam scores, or product sales data.
Advantage and Disadvantage
One of the key advantages of the mode is its resilience against extreme values, similar to the median. Unlike the mean, which can be heavily influenced by outliers, the mode remains relatively unaffected. This makes it a robust measure when dealing with datasets that contain extreme values or skewed distributions.
Additionally, the mode has intuitive appeal. It represents the value that appears most frequently in a dataset, aligning with our natural expectation that the center of a distribution should be represented by its most common value.
However, the mode does have limitations. Like the median, it can be challenging to incorporate into more complex statistical models. Statistical techniques and models often rely on the mean due to its mathematical properties and widespread applicability. The mode, while intuitive, is less commonly used in advanced statistical analyses.
Another drawback of the mode arises when dealing with continuous numerical variables. In cases where variables can take on a wide range of values with small differences (like 1.1, 1.2, 1.3 up to 100.1), determining a single mode can be ambiguous or meaningless. The mode is more suited to discrete numerical variables where values are distinct and identifiable.
Mode of survey example
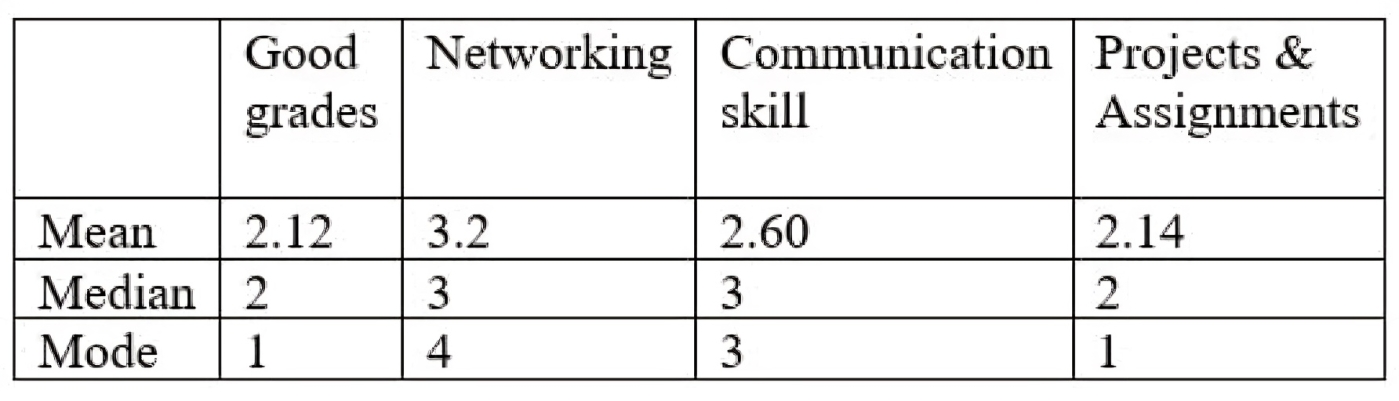
Let’s dive into our example of Key to a great career in data science dataset and determine the mode for each of the variables: grades, networking, communication skills, and projects. The example is common to explain the concept of mean, median and mode, if you have already read the article on mean or median of having a great career in data science you can understand or else you can read it here.
Firstly, for the grade variable, we organize the rankings from least to most common. Students rated grades as follows: 1, 2, 3, and 4. Among these, the most common rating was 1, chosen by 133 students. This makes grades the top-ranked attribute, reflecting its perceived importance. Therefore, the mode for the grade variable is 1.
Moving to networking, the mode is 4. This indicates that among the students surveyed, networking was most frequently ranked as the least important attribute for a successful career in data science.
For communication skills, the mode is 3, suggesting that it was commonly ranked in the middle among the surveyed students in terms of importance.
Lastly, projects also have a mode of 1, indicating that a significant number of students considered practical projects as highly important for a successful career in data science, similar to grades.
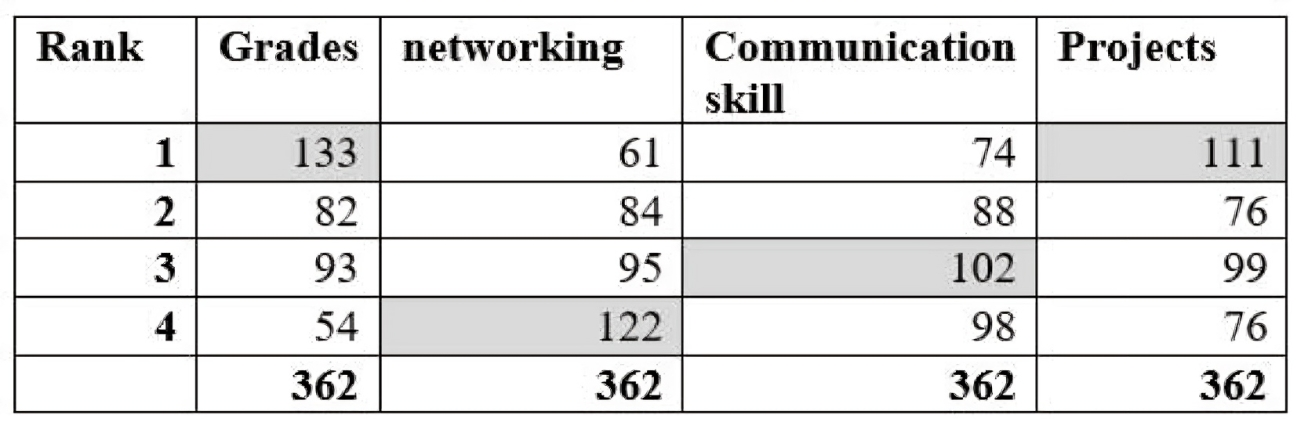
This table of modes provides a snapshot of how students prioritize these attributes. It highlights the attributes that are consistently perceived as crucial versus those that are less emphasized according to the surveyed population.
If we look at the mode, we can compare it with the median and the mean. The mean the most important quality was grade, if you look at the median the most important quality was either grade or projects, we have a tie in that case the 50th percentile is two. if we look at mode the least important is networking and it also confirms that the grade is the number one factor that decide a better career in data science. We can see that across all three measures of central tendency across all three calculations we get a similar sort of finding.